大数据项目-社交案例分析

大数据项目-社交案例分析
康弟弟0.前言
由hadoop搭建完成后,实现一个简单的数据分析案例。
1. DataGrip使用教程
前面搭建好的hive,使用DataGrip编辑器可用更具可视化的看见和执行相关的sql,和IDEA一样的,专业版需要破解,建议下载2024.1.X,方便破解,方法自行百度,以下使用2024.1.5进行演示。
- windows创建工程文件夹
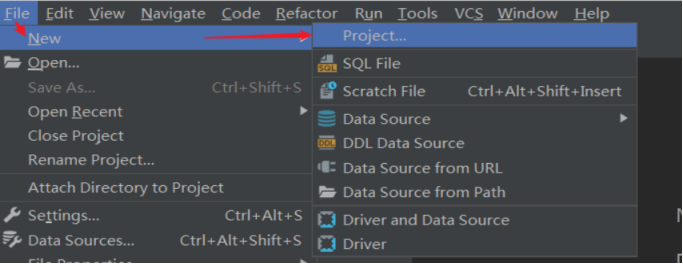
- DataGrip中创建新Project
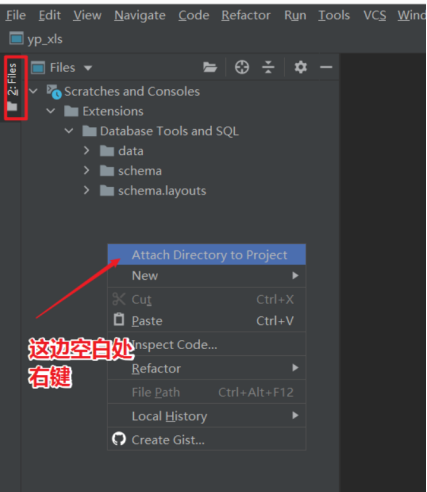
- 关联本地工程文件夹
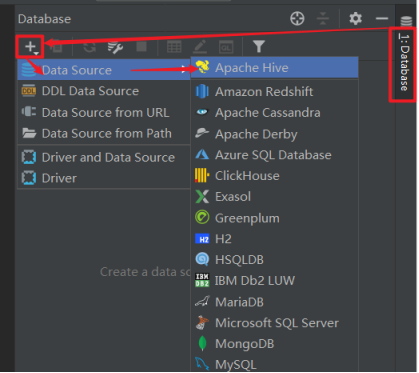
- DataGrip连接Hive
- 配置Hive JDBC连接驱动
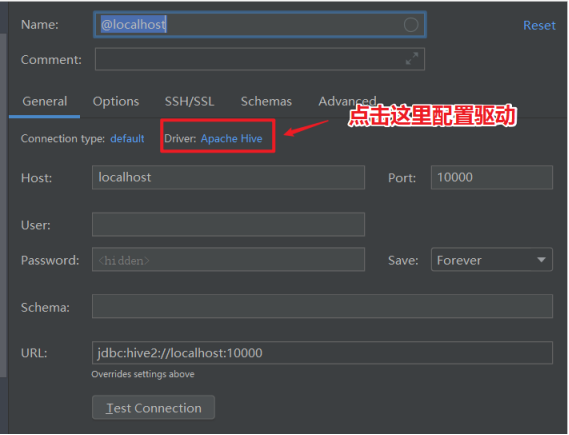
- 配置Hive JDBC连接驱动
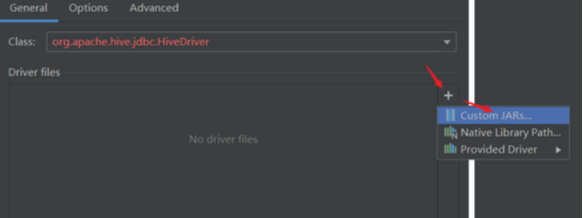
- 返回,配置Hiveserver2服务连接信息
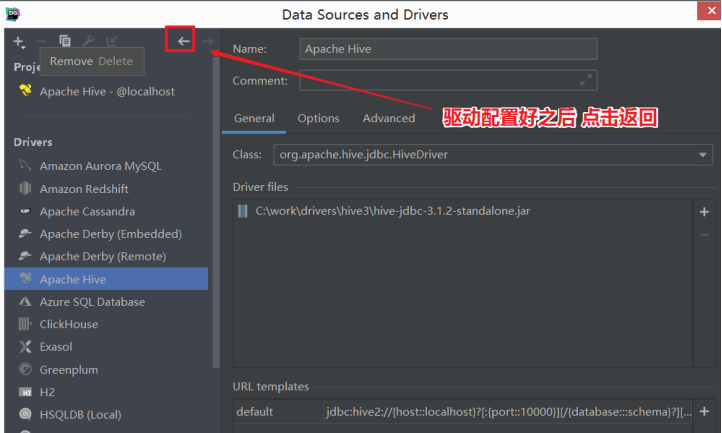
- 返回,配置Hiveserver2服务连接信息
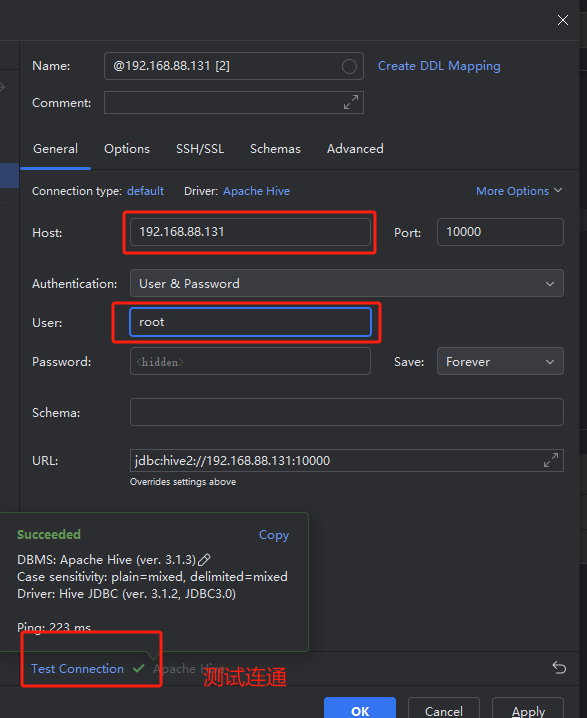
2. 导入数据
2.1 导入数据
- 将下载好的30万条数据添加到文件夹中
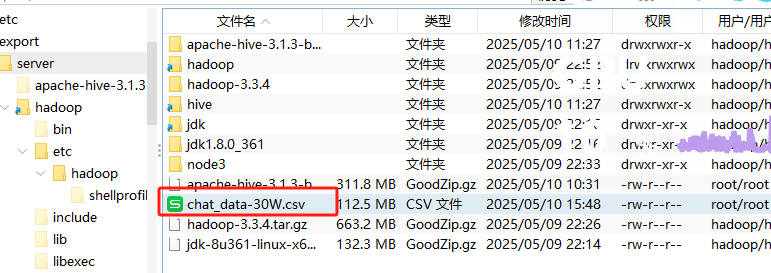
- 在DataGrip中运行以下命令,创建相应的库和表
1 | -- 创建数据库 |
- 在hadoop用户下,运行以下,将数据挂载到hadoop中:
1 | -- 上传数据到HDFS(Linux命令) |
在DataGrip中使用HDFS加载数据:
1
2-- 加载数据到表中,基于HDFS加载
load data inpath '/chatdemo/data/chat_data-30W.csv' into table tb_msg_source;2.2 数据验证
1 | -- 验证数据加载 |
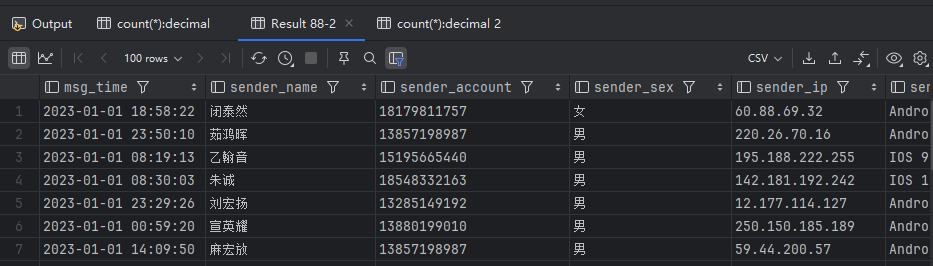
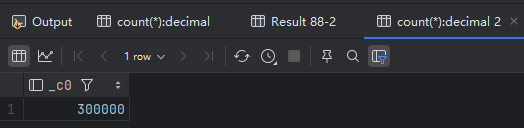
3. 数据清洗
3.1 清洗无效数据
- 创建一张新表,存放有效数据,同时将时间和经纬度分开存放。
1 | create table db_msg.tb_msg_etl( |
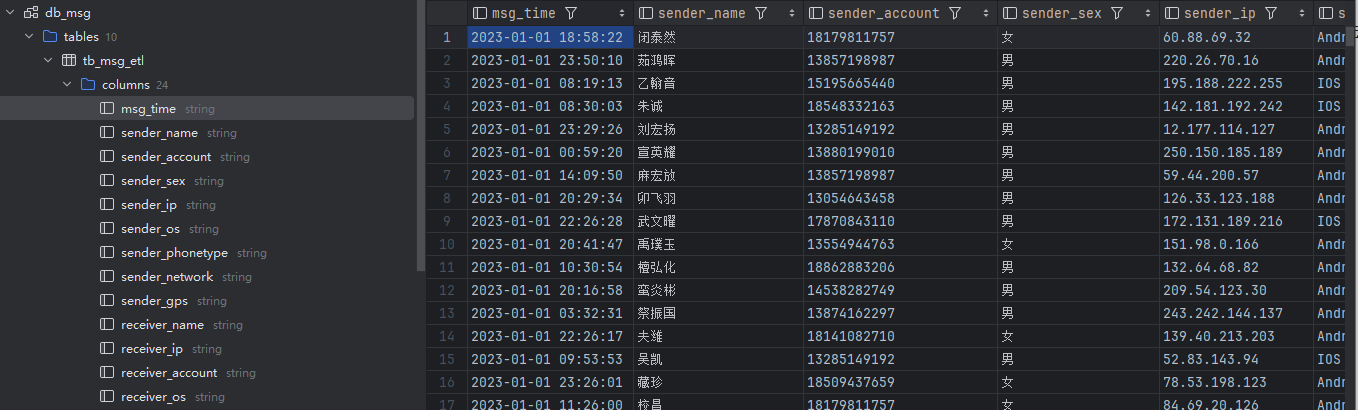
3.2 统计需要的数据
筛选每日消息总量
1
2
3
4
5
6
7
8--保存结果表
CREATE TABLE IF NOT EXISTS tb_rs_total_msg_cnt
COMMENT "每日消息总量" AS
SELECT
msg_day,
COUNT(*) AS total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;每小时消息量趋势
1 | --保存结果表 |
- 各地区发送消息总量
1 | CREATE TABLE IF NOT EXISTS tb_rs_loc_cnt |
- 今日发送消息人数、接受消息人数
1 | --保存结果表 |
- 发送消息条数最多的Top10用户
1 | --保存结果表 |
- 接收消息条数最多的Top10用户
1 | CREATE TABLE IF NOT EXISTS db_msg.tb_rs_r_user_top10 |
- 发送人的手机型号分布
1 | CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_phone |
发送人的OS分布
1
2
3
4
5
6
7
8--保存结果表
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_os
COMMENT "发送人的OS分布" AS
SELECT
sender_os,
COUNT(sender_account) AS cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_os
3.2 查看输出
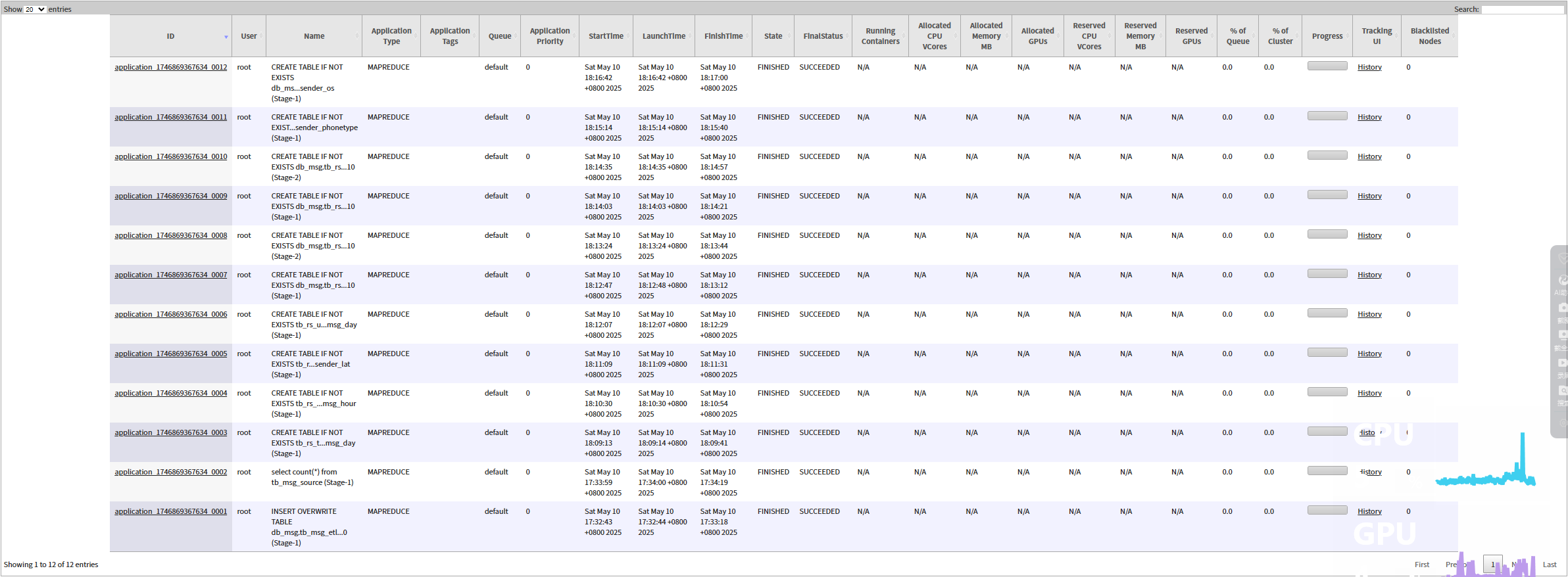
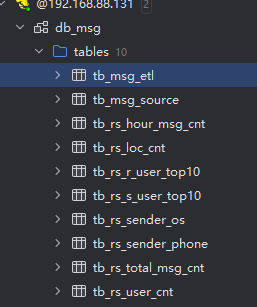
4. 常见问题
4.1 链接超时
- DBMS: Apache Hive (no ver.) Case sensitivity: plain=mixed, delimited=exact Could not open client transport with JDBC Uri: jdbc:hive2://192.168.88.131:10000: java.net.ConnectException: Connection refused: connect.
解决方法:
hiveserver2开启后需要等待一段时间后,才可以使用DataGrip进行链接
关闭3台主机的所有防火墙
systemctl stop firewalld
systemctl disable firewalld
4.2 叶子队列
- [08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1746866980382_0003 to YARN : root is not a leaf queue
这个错误信息表明在执行 Hive 查询时,MapReduce 任务提交到 YARN 时失败了,原因是 root 队列不是一个叶子队列。
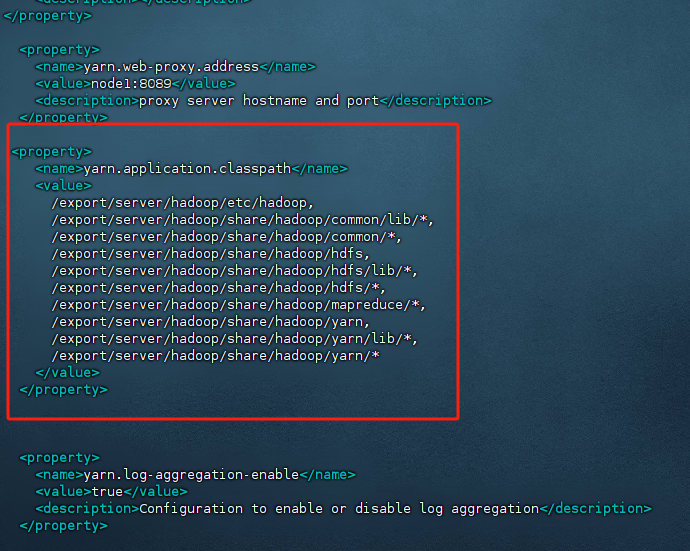
解决:将Hadoop 类路径 hadoop classpath添加到yarn-site.xml
hadoop用户下输入hadoop classpath

将上述内容添加到 /export/server/hadoop/etc/hadoop/yarn-site.xml
4.3 无法将文件写入HDFS
- [08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. File /tmp/hadoop-yarn/staging/root/.staging/job_1746864917228_0005/libjars/hbase-replication-2.0.0-alpha4.jar could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2315) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:29 …
解决:
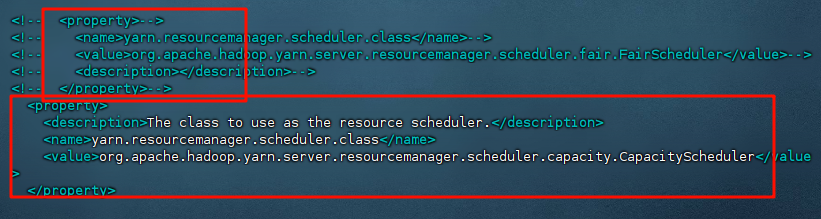
- 修改文件分发策略,修改 /export/server/hadoop/etc/hadoop/yarn-site.xml,将原来的resourcemanager.scheduler.class修改为capacity策略
1 | <property> |
4.4 文件写入失败
和上述的情况很相似:08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. File /tmp/hadoop-yarn/staging/root/.staging/job_1746856477845_0009/libjars/hive-service-rpc-3.1.3.jar could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2315) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:29 …
错误分析
- 文件写入失败:文件 hive-service-rpc-3.1.3.jar 没有被复制到任何 DataNode 上。
- minReplication nodes:配置的最小副本数是 1,但文件没有成功复制到任何一个 DataNode 上。
- 有 3 个 DataNode 正在运行,但有 3 个节点被排除在此次操作之外。
可能的原因
- DataNode 故障:可能所有的 DataNode 都出现了故障,导致文件无法写入。
- 网络问题:可能存在网络问题,导致 NameNode 无法与 DataNode 通信。
- HDFS 配置问题:HDFS 的配置可能不正确,例如副本系数设置不当。
- 权限问题:用户 root 可能没有足够的权限写入 HDFS。
- 资源不足:DataNode 的磁盘空间可能不足。
解决步骤
检查 DataNode 状态:
bash
复制
1
hadoop dfsadmin -report
查看所有 DataNode 的状态,确保它们都是正常的。
检查 HDFS 配置:
检查 hdfs-site.xml 中的配置,特别是副本系数(dfs.replication)的设置。
检查文件权限:
确保用户 root 有足够的权限写入 HDFS。
bash
复制
1
hadoop fs -ls /user/hive/warehouse
检查磁盘空间:
确保所有 DataNode 有足够的磁盘空间。
bash
复制
1
df -h
重启 HDFS 服务:
尝试重启 HDFS 服务,包括 NameNode 和 DataNode。
bash
复制
1
2sudo systemctl restart hadoop-hdfs-namenode
sudo systemctl restart hadoop-hdfs-datanode检查日志文件:
查看 Hadoop 和 Hive 的日志文件,获取更多错误信息。
5. 尾
没啥好说的,这里的很多错误都是我踩过的,改了好几个小时才解决的,下一篇就是数据可视化了。








